
Бутылочное горлышко.
Внимательный читатель после первых двух частей закономерно спросит: «Что же мы постоянно говорим о табличных блокировках? Неужели SQL Server умеет блокировать только таблицы целиком?». Конечно же, это не так. При правильной организации архитектуры системы пользователи вообще не должны сталкиваться с табличными блокировками. Правда, мы живем не в идеальном мире, поэтому и были написаны предыдущие две главы.
Теперь же рассмотрим более сложный случай, когда пользователи захватывают только те данные, которые им действительно нужны, не больше, но и не меньше.
Для примера разберем типичный сценарий работы оператора в 1С 8. В работе других систем тоже возможны подобные проблемы — внимательно следите за описанием механизма! Ситуация будет намеренно упрощена, но актуальноcть проблемы при этом не потеряется.
Итак, диспозиция: в системе есть документ «Реализация товаров», регистрирующий факт отгрузки товаров со склада. Также, есть регистр остатков «Товары», хранящий информацию о приходе/расходе товаров.
Фактически, «регистр» состоит из двух таблиц:
- Непосредственно таблица движений, хранящая отдельные записи по каждой операции («плюс» и «минус»)
- Таблица итогов регистра, хранящая предрассчитанные суммы движений на начало каждого месяца. Без таблицы итогов каждый отчёт по остаткам регистра был бы вынужден суммировать все детальные записи «от начала времён». Таблицы итогов позволяют найти ближайший итог и далее использовать детальные записи только для подсчета «дельты», накопившейся от начала месяца до нужной даты отчёта.
Для каждой комбинации ключевых полей регистра («измерений») хранится отдельная запись со своим итогом. За синхронизацией данных «итогов» и «детальных записей» следят встроенные механизмы платформы 1С.
В момент, когда оператор проводит новый документ, делается новая запись в таблицу детальных движений регистра «Товары», а также изменяется соответствующая запись в таблице итогов. Тут-то и начинаются проблемы. Очевидно, что добавление новой записи в таблицу никому не мешает. А вот существующая запись с данными об остатке — это ресурс, за доступ к которому может быть достаточно высокая конкуренция! В результате, пользовательские транзакции, списывающие один и тот же товар, выстраиваются в очередь; менеджеры в этот момент откладывают разрывающийся телефон и уходят за новой чашкой кофе.
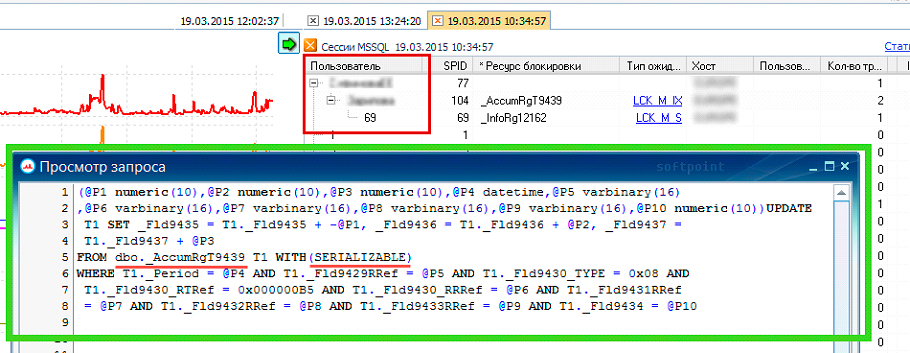
Есть несколько основных способов разрешения таких коллизий, причем применять их можно как по-отдельности, так и вместе.
Первое. Если пользователи сталкиваются друг с другом при обращении к одному и тому же ресурсу — давайте просто дадим каждому по своему ресурсу! На первый взгляд звучит дико, но идея не такая уж и безумная. Надо проанализировать состав полей, к которому обращаются пользователи, и подумать, не можем ли мы добавить какой-то дополнительный разрез? Например:
- пользователям нужны остатки по товару — может быть, мы можем хранить остатки отдельно по каждому складу?
- склад уже используется (что логично) — давайте подумаем об отгрузке в разрезе заказов!
- и т.д.
В самом плохом случае, когда делить уже дальше некуда — можно подумать о введении искусственного поля-разделителя. Именно этим путем, кстати, пошла фирма 1С — если в свойствах регистра накопления включить галку «Разделение итогов», в таблице итогов появится дополнительное поле «_Splitter», назначение которого — разрешить одновременную запись по одному и тому же набору измерений из разных сессий. Получается, 2 сессии параллельно могут списывать со склада одни и те же «табуретки», при этом у одной _Splitter будет равен 0, у другой — какому-то другому числу. А при обращении к остаткам записи просуммируются без учёта «разделителя». Да, это сложнее, чем посмотреть в одной-единственной записи-итоге, зато всё ещё быстрее, чем перебор всех детальных записей.
Второй подход — уменьшение времени блокировки конкурентного ресурса. В самом деле, чем меньше транзакция держит ресурс, тем меньше вероятность столкновения с другой транзакцией. Помним, что ресурс считается захваченным с момента наложения блокировки и до окончания транзакции. Это значит, что блокировку следует накладывать как можно позже (но без ущерба бизнес-логике!).
Третье, про что не стоит забывать при оптимизации блокировок — применяемый уровень изоляции транзакций. Уровень изоляции влияет на то, в какой момент накладывается блокировка. Считывание данных с завышенным уровнем изоляции транзакций может привести к избыточной блокировке конкурентных транзакций. Например, если мы считываем остаток товара с уровнем изоляции «SERIALIZABLE» или «REPEATABLE READ», ни одна другая транзакция уже не может прочитать те же самые данные. Но если бы вместо этого использовался уровень изоляции «READ COMMITTED» или ниже, читающие транзакции не встретили бы никаких препятствий.
Понятно, что понижение уровня изоляции транзакций не всегда приемлемо. Но при разборе проблем с массовыми блокировками всегда следует учитывать и эту возможность.
Как видим, в ситуации со страничными блокировками и блокировками по ключу нет «волшебной кнопки», одним движением заставляющей систему работать. Здесь уже необходим вдумчивый анализ ситуации и поиск правильного баланса между производительностью и требованиями бизнес-логики. Именно опыт принятия таких решений отличает опытного системного архитектора от начинающего специалиста.
Растет, как на дрожжах
Со следующей проблемой чаще всего сталкиваются начинающие администраторы (особенно те, кто не любит вдаваться в особенности функционирования механизмов СУБД).
Итак, ситуация: компания решила перейти на MS SQL Server, купила лицензии, под СУБД выделен новый сервер, от одного вида которого запросы должны выполняться за доли секунды. База развернута, выбран самый «продвинутый» режим восстановления данных — «Полный», с возможностью откатить изменения с точностью до секунды. Настроено резервное копирование файла данных с таким расчетом, чтобы меньше всего мешать пользователям — в обед и вечером, когда все уже уходят с работы. Казалось бы, администратору БД осталось сидеть, смотреть на идиллическую картину чужой работы и радоваться. Но…
Через несколько дней выясняется, что файл лога транзакций неожиданно разросся до ощутимых размеров и угрожает занять собой все место на диске. «Разросся? Не беда! — думает начинающий администратор — сейчас мы его усечем, чтобы неповадно было!» И добавляет в расписание к резервному копированию дополнительную команду: «shrink file» [здесь команда специально максимально сливается с текстом, чтобы иной читатель при беглом просмотре нечаянно не «научился плохому»]. Так вот, добавляет администратор эту команду, файл лога транзакций послушно сжимается, а на следующий день, с самого утра пользователи начинают сталкиваться с такими блокировками

LATCH — это «младший брат» привычной нам блокировки. Тоже блокировка, но работающая на более низком — физическом — уровне, т.е. речь уже идет не о записях в БД, а о физических ресурсах сервера. В данном случае контролируется доступ к подсистеме ввода-вывода. Ну а описание ресурса блокировки подсказывает, что пользователи ждут окончания расширения файла лога транзакций.
Особенно неприятно в этой ситуации то, что для приращения лога транзакций недостаточно просто разметить место на диске, СУБД необходимо обязательно заполнить выделенное пространство нулями (это обусловлено внутренней механикой лога транзакций). При этом, в течение всей долгой операции приращения лога пользователи не могут ни изменять, ни вводить новые данные.
«И такая дребедень — целый день»: в течение дня лог периодически увеличивается, за ночь усекается и на следующий день ситуация повторяется. На эффективности работы пользователей это сказывается самым плачевным образом.
Разберемся, почему так происходит.
Для начала, что такое лог транзакций? Это специальный файл, предназначенный для приема входящего потока данных. Такая схема сильно разгружает основной файл данных, а на уровне СУБД организуется своеобразное разделение труда:
- Лог транзакций — содержит «свежие» данные, в том числе и от тех транзакций, которые еще не завершились и могут быть отменены. Быстро принимает данные, не затормаживая входящий поток от пользователя
- Основной файл данных — содержит зафиксированные данные завершенных транзакций. Не занимается обслуживанием входящего потока, зато оптимизирован для извлечения запрашиваемых данных.
Данные из лога транзакций рано или поздно должны быть перенесены в основной файл данных. Страницы, не перенесенные в основной файл данных, называются «грязными»; напротив, перенесенные страницы отмечаются как готовые к перезаписи. Именно так: правильно обслуживаемый лог транзакций перезаписывается по кругу. Загвоздка именно в том, когда же грязные страницы можно будет перезаписать.
Для этого должно выполниться несколько условий:
- Во-первых, транзакция, в которой были получены эти страницы, должна завершиться — данным незавершенных транзакций в основном файле делать нечего.
- А вот «во-вторых» зависит от модели восстановления: при «простой» модели восстановления СУБД периодически сама отмечает страницы как перезаписываемые. Но при работе в модели восстановления «Полный» страницы освобождаются только при выполнении резервной копии журнала транзакций! Поэтому, при работе с такой моделью восстановления рекомендуется делать такие копии достаточно часто — раз в час или даже в полчаса.
Правильное обслуживание лога транзакций позволит избежать его неконтролируемого раздувания — размер должен зафиксироваться в пределах трети от размера файла данных (а может быть и много меньше — зависит от информационного потока). Пользователи перестанут сталкиваться с ожиданиями расширения файла, а администратор БД получит удобный механизм восстановления данных с точностью до транзакции.
Напоследок, важное замечание: для восстановления данных в «полной» модели восстановления необходима непрерывная цепочка бэкапов логов с момента последнего полного бэкапа. Если вдруг в этой цепочке одно из звеньев «выпадет», восстановление остановится на образовавшейся бреши и все остальные данные будут потеряны. Это следует из способа восстановления: по сути, копии журнала транзакций содержат последовательный список команд, переданных базе. Если нарушить порядок выполнения этих команд или пропустить часть из них, гарантировать целостность данных будет невозможно.
Временные данные.
Среди всех служебных баз данных, создаваемых MS SQL Server, чаще всего упоминается только одна – tempdb. Именно в этой базе данных хранятся временные таблицы, данные, используемые во время группировок и другие служебные записи. Другими словами, практически каждый сеанс, работающий с БД, рано или поздно обратится к tempdb с запросом на чтение или изменение данных.
Неудивительно, что база tempdb часто становится бутылочным горлышком производительности – большой поток обращений к одному и тому же ресурсу приводит к тому, что база оказывается не в состоянии обслужить все транзакции. Появляются очереди обслуживания, блокировки на доступ к физическим ресурсам (жесткому диску), пользовательские транзакции замедляются…
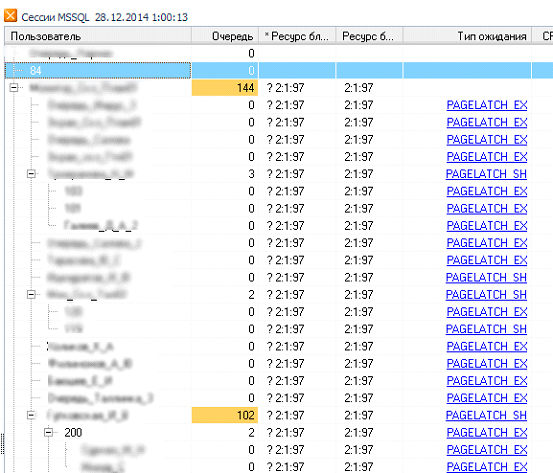
Дерево блокировок при обращении к базе tempdb. База tempdb всегда имеет ID 2
Самый простой способ уменьшить конкуренцию за низкоуровневый доступ к файлу tempdb –разбить этот файл на несколько равных частей. С размером каждой части лучше не экономить – конечно, можно настроить автоприращение файла, но в предыдущей части мы уже разбирали, что каждая операция приращения приводит к «заморозке» транзакций, в данный момент работающих с файлом. Конечно, приращение файла данных tempdb обычно происходит гораздо быстрее, чем приращение лога транзакций, но если изначально есть возможность избежать лишних торможений – почему бы ей не воспользоваться?
Поэтому просто засекаем размер файла данных tempdb после рабочего дня (но до перезагрузки сервера!) и разбиваем его так, чтобы сумма размеров частей давала тот же объем. Почему важно избежать перезагрузки? Потому что после перезапуска SQL Server уменьшает размер файлов tempdb до того, который указан в настройках (initial size). В результате, мы не увидим, какой размер фактически необходим нашим пользователям.
На сколько частей разбивать файл tempdb? Хороший вопрос. Долгое время в среде DBA существовало правило: «по одному файлу данных tempdb на ядро процессора». С тех пор прошло много времени, процессоры вместо частоты начали меряться ядрами и теперь слепое следование этому правилу может привести к тому, что СУБД придется командовать табуном из 32 мелких файликов. Начиная с какого-то момента (зависит от системы – у кого-то раньше, у кого-то – позже) издержки на управление несколькими файлами начинают перевешивать выгоду от уменьшения конкуренции за единый файл временных данных. Поэтому, на текущий момент, правильный принцип таков: «разбить файл данных tempdb на 8 одинаковых частей. Мониторить ситуацию пару дней. Если блокировки на физический доступ к файлам останутся, добавить еще четыре части. Повторять, пока ситуация с блокировками не выправится, либо пока число файлов не превысит число процессорных ядер».
И, напоследок, важное отступление для слишком дотошных администраторов. В среде юристов и экономистов есть важное понятие — «цена вопроса»: важно понимать, стоят ли потраченные усилия предполагаемой выгоды. Другими словами, мы можем потратить месяц работы юриста на пару с бухгалтером и доказать, что компания должна платить меньше налогов. Но если компания небольшая и тем самым мы сэкономим только пару тысяч рублей в месяц – стоит ли это месяца работы высокооплачиваемых специалистов?
В среде администрирования постоянно приходится вспоминать о «цене вопроса». Причем, как прямой (время, потраченное администратором и программистом – читай, их зарплата), так и косвенной: часто изменения в системе приводят не только к улучшению исследуемого показателя, но и к деградации в какой-то другой области.
Говоря уже совсем прямо: никогда не стоит добиваться «исключения конфликтов блокировок как класса». Если в системе наблюдается несколько конфликтов блокировок в неделю и пользователи теряют на этом несколько минут – на этом оптимизацию можно остановить. Экономия нескольких минут в неделю не сравнится с часами, которые будут затрачены на финальную доводку, тем более, что успех ее не гарантирован.
Be the first to comment on "Массовые блокировки в работе ИС ч.2"